前面的文章讲到了业务容器化改造的思路和方案,主要是从三个方面进行:业务的微服务化拆分、构建自动的CI/CD发布流水线、搭建容器平台,并详细介绍了相关的方案。本编文章是本系列的最后一篇,以实际的案例讲解如何实现电商业务的容器化。
一、项目背景介绍
该电商平台采用全开源的技术框架,其设立的目标是在于帮助中小企业快速搭建属于自己的电商平台。主要功能点是,具备完善的购物流程、后端运营平台对前端业务的支撑,同时具备对系统运行的各种指标的监控和运维体系,保证系统能够独立正常运行。
整个电商平台采用的是前后端分离的架构,前端使用Vue,主要实现的是电商平台的前端商城网站,顾客的登录网页,以及后端的运营平台网站。后端使用SpringCloud,将业务的主要功能进行微服务化,主要的功能除了SpringCloud自身的注册中心(Eureka)、配置中心(Config)、监控中心(Monitor)、日志采集中心(Zipkin)、服务网关(Zuul)及其他配套功能之外,业务功能方面拆分为数据中心、订单中心、支付中心、对接中心、任务中心、用户中心、认证中心。同时在项目中使用了RabbitMQ消息中间件、Redis缓存数据库、Mysql数据库。
项目容器化的最终目标是,将上述的所有功能组件全部以容器的形式运行,并且能够实现业务系统服务模块的高可用,以及面对业务高峰时期的自动扩缩容,同时具备快速的业务变更与上线能力。
二、业务容器化技术方案
前文中讲到业务容器化的思路主要是三个方面:一是业务的微服务化拆分,二是业务发布流程的自动化,三是构建容器云管理平台。由于该电商平台项目本身已经是微服务化的,因此在这里不做如何进行微服务拆分的介绍。最终我们选择利用Rancher和Harbor搭建基于Kubernetes的容器云管理平台,利用Gitlab搭建了代码仓库,利用Jenkins搭建了持续集成交付的平台,具体的部署方式可以参考本系列的其他文章。本篇主要介绍电商平台项目如何进行容器化,和构建自动化的CI/CD发布流水线。
业务容器化改造的思路和方案,可参考本系列的第一篇文章:业务容器化改造的思路与方案
微服务化拆分的原则、技巧和方法,可参考本系列的第二篇文章:业务微服务拆分
利用Rancher和Harbor搭建容器管理平台,可参考本系列的第三篇文章:搭建容器平台和私有镜像仓库
利用Gitlab搭建私有的代码仓库,可参考本系列第四篇文章:在k8s中部署gitlab代码仓库
利用Jenkins搭建持续集成交付平台,可参考本系列第五篇文章:在k8s中部署Jenkins持续集成交付平台
使用Jenkins构建CI/CD发布流水线的方法,可参考本系列的第六篇文章:构建自动的CI/CD发布流水线
2.1 构建容器云管理平台
我们选择Kubernetes作为容器云管理平台,除了官方开源的kubernetes平台之外,各大公有云厂商也都推出了公有云版本的kubernetes平台,比如:阿里云的ACK(Aliyun Container Service for Kubernetes)、腾讯云的TKE(Tencent Kubernetes Engine)、华为云的CCE(Cloud Container Engine)、谷歌的GKE(Google Kubernetes Engine)、亚马逊的EKS(Amazon Elastic Container Service for Kubernetes)、微软的AKS(Azure Kubernetes Service)等。还有一批厂商推出了可私有部署的kubernetes平台或管理平台,比如:IBM的ICP(IBM Cloud Private)和Rancher公司的RKE(Rancher Kubernetes Engine)都是可以私有部署的kubernetes平台。另外Rancher公司的Rancher产品是一款kubernetes的管理平台,通过该平台我们可以在私有的物理机、虚拟机或者公有云的云主机上快速安装部署kubernetes平台,也可以直接接管公有云厂商提供的公有云版本的kubernetes集群。
无论是使用公有云的Kubernetes平台还是自建私有的Kubernetes平台,其技术架构基本上一致,都是以服务器层为基础,在其上构建Kubernetes平台,利用命令行或者web界面调用其中封装好的API接口来操纵和使用Kubernetes集群。二者的区别主要是公有云厂商提供了所有的IaaS层资源,用户在其上购买云主机,一键部署kubernetes集群,然后使用,不用关心底层的实现和维护问题,同时公有云厂商提供了完善的配套工具和解决方案:如监控、日志、镜像仓库、应用商店等;而自建私有的Kubernetes平台,需要用户自己准备相关的服务器,然后在其上安装kubernetes集群,再根据需要在其上搭建配套的监控、日志、镜像仓库、应用商店等,同时用户需要根据实际情况去维护自下而上所有的系统和服务。
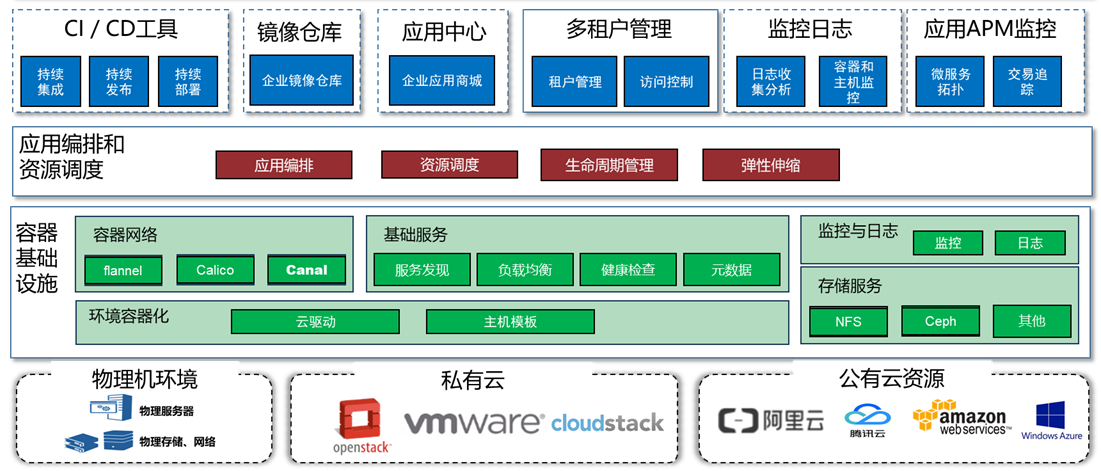
本次我们是利用Rancher自建私有的Kubernetes平台,同时搭建Harbor私有镜像仓库,最终建好的Kubernetes平台主要由四层组成:第一层为基础设施层,包含了服务器、存储、网络等基础资源,其中服务器可以是物理机,基于VMware、OpenStack、CloudStack的虚拟机,甚至是来自公有云的云主机。第二层是容器基础设施层,即docker层,是在服务器主机的操作系统上安装Docker,将底层的环境和资源容器化,形成可以供容器使用的计算资源、存储资源、网络资源等。第三层应用编排和资源调度层,即Kubernetes层,利用Rancher构建Kubernetes平台,将Docker层的资源调度起来,同时可以编排容器,决定容器可以运行几个副本,在哪台主机上运行,遇到压力峰谷时自动扩缩容。最上面一层是应用管理层,即用户可以通过界面对整个平台进行管理,管理台中同时可以提供配套的管理工具,如:CI/CD工具、镜像仓库、应用商店、监控、日志、多租户管理等。
容器云管理平台的架构图如下:
2.2 业务容器化设计
本次的电商平台项目,涉及的组件主要有前台的Vue.js项目,后端的Java项目,配套的数据库、缓存数据库、消息中间件等。项目容器化强调的是将项目的功能模块以容器的形式运行,原则上本项目中所有的组件均可以以容器的形式运行。
项目容器化需要考虑的问题主要是:应用属于有状态/无状态应用?应用如何保证高可用?应用之间如何互相访问?最终用户如何访问应用系统?
2.2.1 应用的状态分析
无状态应用不依赖于存储在应用内的特定数据来向用户提供服务,在同一个应用有多个实例的时候,用户访问到任意的实例都可以获得正常的服务,且得到的结果也是完全一致的。虽然无状态应用在运行的过程中也可能会产生一些数据,当无状态被删除重建之后,原先产生的数据会丢失,但是是否存在这些数据对用户请求的响应结果没有任何影响。无状态应用基本不需要考虑数据的持久化问题,可以说每一个实例都是一样的,因此这类应用适合做快速扩容,多副实例同时对外提供服务,形成负载均衡的能力。常见的无状态应用有网站。
有状态应用需要存储特定的数据来向用户提供服务,为了保证应用在重启之后或者删除重建之后,依然能够像之前一样向用户提供服务,这些特定的数据必须要持久化保存到指定的存储空间中。通常情况下,有状态应用只有一个实例,独享一份数据;特定情况下,也是有多实例的,例如多个实例组成集群,每个实例拥有自己的存储空间,各个实例之间的数据通过集群软件同步的方式保持一致,这样才能保证用户访问到任意实例时都能获得相同的返回结果。有状态应用必须考虑数据的持久化问题,而多实例之间的数据同步难以解决,因此除了应用程序自身具备集群功能(例如,Mysql集群)或者借助外部的数据同步软件(例如,存储同步)之外,只能做到单实例运行,因此有状态应用难以做到快速的扩容。常见的有状态应用有数据库、消息中间件等。
因此,针对本项目,我们将项目的所有功能组件进行分析并归类,如下:
| 序号 | 功能组件 | 说明 | 有/无状态 |
|---|---|---|---|
| 1 | 前端Vue.js项目 | 前台网站,仅作展现,不存储数据。 | 无状态 |
| 2 | 后端Java项目 | 后端业务逻辑,仅作业务处理,不存储数据。 | 无状态 |
| 3 | Mysql | 数据库,用于存储所有的业务数据。 | 有状态 |
| 4 | Redis | 内存数据库,用于缓存业务过程数据,数据基本存储在内存中,定期写盘。 | 有状态 |
| 5 | RabbitMQ | 消息队列,存储请求队列。 | 有状态 |
2.2.2 应用的高可用设计
由上述分析,可知前端的Vue.js项目和后端的Java项目均属于无状态应用,因此每个功能模块均可以运行多个实例(容器)来实现功能模块的高可用。每个功能模块,前端可以配置一个Kubernetes平台中的服务作为统一入口,对外提供服务,同时也具备了负载均衡的能力。同时当业务高峰来临时,Kubernetes平台可根据预设的资源使用阈值,动态调整每个功能模块运行的实例(容器)数,实现自动的动态扩缩容。
Mysql、Redis、RabbitMQ等配套数据库和中间件,都属于有状态应用,无法像无状态应用那样直接启用多个实例,因此需要考虑使用集群的方式实现高可用。这三类软件在Rancher的应用商店中都有对应的集群Chart包,分别是:mysqlha、redis-ha、rabbitmq-ha,可以直接部署使用。
2.2.3 应用访问的设计
非容器化部署的时候,商城项目后端项目采用的是SpringCloud的微服务架构,每个后端功能模块都有一个服务名,相互之间通过服务名进行调用访问。前端Vue.js项目访问后端Java项目,以及后端Java项目访问Mysql数据库、Redis缓存、RabbitMQ消息队列时,均通过主机名的方式访问,相应的访问地址(主机名)及用户名密码都写在固定的配置文件中。
使用容器部署时,无论是前端项目,还是后端项目,还是配套的数据库等,无法使用主机名或者IP地址的方式来访问,因为存在多容器运行同一类业务功能,主机名不唯一;容器可能会随时重启、重建,其主机名和IP也可能在重启后发生改变。因此需要采用Kubernetes的服务(Service)方式,在运行一个业务功能的所有容器之前,设置一个对应的Kubernetes服务(Service),Service中包含了服务名、IP地址和服务端口,以及后端对应的一组容器。服务名在设置之后可以保持不变,且具备负载均衡功能,当用户访问服务名时,将会自动将访问请求分发到后端对应的容器上。
对内,Kubernetes集群内置了DNS服务器,可以自动解析服务名和IP地址的对应关系,可实现通过Kubernetes服务(Service)的方式实现相互之间的访问。对外,可以通过NodePort、LoadBlancer、Ingress等方式,将内部的服务暴漏到外部,让最终用户可以访问。NodePort的方式是将服务的端口映射到所有宿主机的某个端口上,通过访问任意一个宿主机的IP和端口来实现访问;Ingress的方式是将一个域名和Kubernetes内部的服务名和服务端口映射,这个域名对应IP地址是所有的宿主机IP地址,需要在外部DNS上配置或在hosts文件中配置,通过访问域名的方式来实现访问;LoadBlancer的方式是借用外部的负载均衡器将请求转发到Kubernetes集群内部的服务上,通过访问负载均衡器的地址来实现访问,这是标准的将服务暴露到外部的方式。
2.2.4 总结
因此当业务容器化之后,所有的项目功能模块均以容器的形式在容器云平台中运行,每个功能模块均采用“前端服务+后端应用容器”的方式运行,各功能模块之间通过服务名的方式互相访问,外部用户通过暴漏的入口访问应用系统。其中每个无状态应用可以运行多个容器,对应到前端的一个服务上,形成高可用和负载均衡;有状态应用可以以集群的形式运行多个容器,实现高可用,挂载外部的存储实现数据持久化。
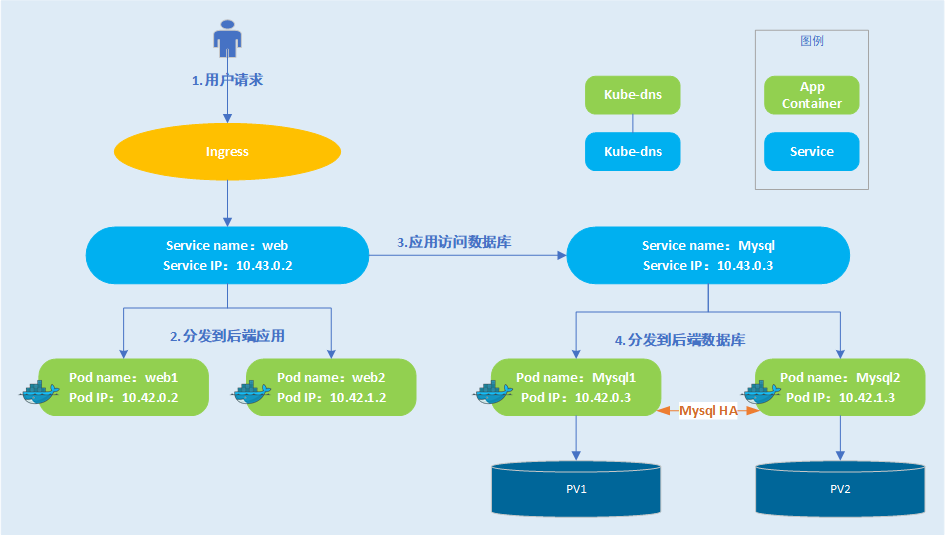
下图是业务容器化之后的一个示例,选择了本次项目中的两个组件:前端web服务和后端mysql数据库服务。前端web服务是无状态的,下面对应两个运行web应用的容器;web服务通过Ingress的方式暴漏到外部。后端mysql数据库服务是有状态的,下面对应一个Mysql HA集群,每个mysql节点有自己的存储盘。
用户通过Ingress访问web服务时,访问请求将自动分发到后端运行的web容器中,web容器通过web服务访问mysql服务,mysql服务将请求转发给后端运行mysql的容器中,后续再将结果层层返回给用户。
2.3 构建基于容器的CI/CD平台
在构建CI/CD发布流水线之前,我们在Kubernetes容器云管理平台中搭建了容器化的Gitlab代码仓库和Jenkins持续集成交付工具集。
Gitlab中新创建项目,并上传商城系统的代码,每个独立部署的功能模块的代码作为独立的项目,在Gitlab中对应自己的代码仓库。涉及到代码的功能模块为前端的Vue.js项目和后端的Java项目,配套的数据库、缓存等不涉及代码。
Jenkins自身支持Master-Slave架构,即使用一个Jenkins作为Master服务器(节点),用于管理多个Slave服务器(节点),Slave服务器的用途是执行具体的构建任务,这样的好处是将构建任务的压力分摊给多个Slave节点来执行,避免master的压力过大造成的构建任务阻塞。
Jenkins支持基于kubernetes的Slave,即可以在kubernetes集群中启动jnlp容器,作为Slave服务器来执行构建任务,这样将带来更多的好处:
- 容器化
Jenkins Slave节点是运行在kubernetes集群中的一个POD,该POD中可以有多个具体执行构建步骤的容器,容器本身的环境是标准化的,可以自己定制容器镜像,具备很强的版本控制和可移植性。同时每个构建任务具备自己的Slave节点,与其他构建任务之间具备很好的隔离性。 - Slave容器全生命周期管理
当构建任务触发时,将会自动在kubernetes集群中创建用于本次构建的Slave节点,并自动在其中执行构建任务,当构建任务结束时(无论是成功或失败)将自动销毁该Slave节点,并释放资源。 - 高并发
当有多个构建任务同时触发时,将会在Kubernetes集群中创建多个用于执行构建任务的Slave节点。 - 资源共享
所有用于执行构建任务的Slave节点共享一个Kuberenetes集群的资源。
因此我们采用Master Slave的架构来部署Jenkins,在Kubernetes中部署持续运行的Jenkins Master,在Jenkins中配置用于执行构建任务的Jenkins Slave,Slave节点只在执行构建任务的时候才会启动运行。
2.4 构建CI/CD发布流水线
利用Gitlab和Jenkins构建CI/CD发布流水线时,考虑到流水线的配置管理和版本管理,以及随代码的快速迁移性,采用了“流水线(Pipeline)”的方式来实现,将运行任务的Jenkins-Slave节点、执行的步骤等全部配置到Jenkinsfile文件中。在新建任务的时候,只需配置代码仓库,并选择Jenkinsfile即可;之后执行构建的时候将自动依照Jenkinsfile中定义好的步骤执行操作。
在Jenkinsfile中定义构建步骤时,可以根据实际的业务情况,加入代码质量检查、代码测试、代码的编译、软件制品归档、制作容器镜像、部署到Kubernetes集群、通知任务执行结果等步骤;根据实际的业务逻辑,设定步骤之间或者任务之间的串行和并行。
配置任务时,可以根据实际需要配置任务执行的触发器,可根据实际情况配置为定时轮询触发、自动触发或手动触发。如果为了实现快速的代码测试及功能发布测试,即每一次提交代码之后需要立即查看构建结果时,可以采用自动触发的方式;如果是需要正式上线,建议在触发之前,加一步人工确认环节,确认代码功能正常、符合上线要求之后,再触发构建任务,保证上线成功。
2.4.1 CI/CD发布流水线原理
通常情况下,针对一个项目,利用Gitlab和Jenkins构建的CI/CD发布流水线的原理如下图所示。
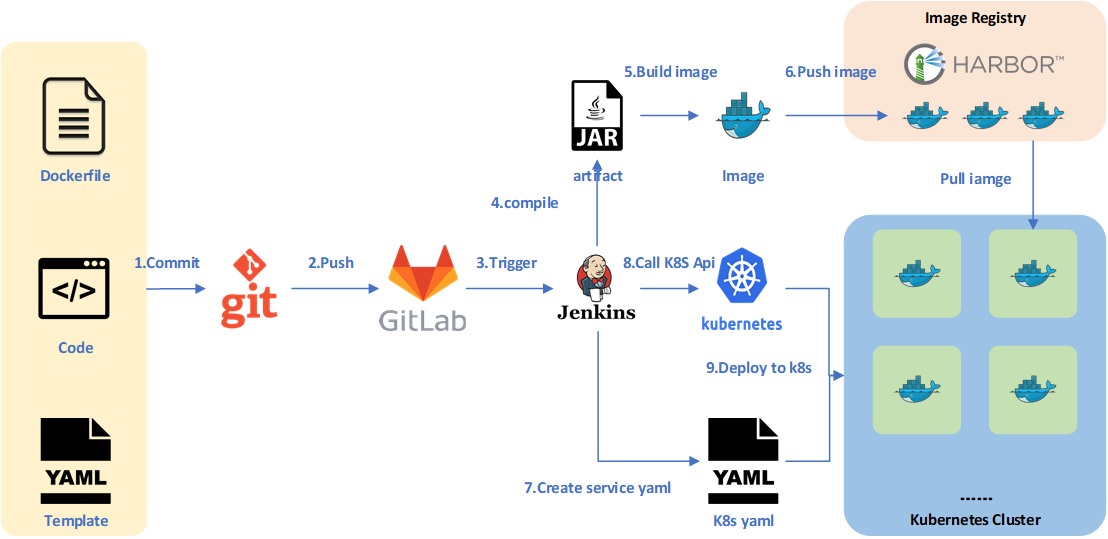
- 开发人员编写好程序代码,通过git提交到本地的代码仓库,提交时,需要包含后续打包成镜像的Dockerfile,以及部署到Kubernetes集群中的YAML资源配置模板。
- 将本地所有的程序代码及相关的配置文件都推送到远端的gitlab代码仓库服务器中,进行统一的管理。
- gitlab与jenkins之间配置有webhook,可以触发jenkins进行后续的集成和交付步骤。
- Jenkins配置的流水线任务触发之后,会自动拉取gitlab中的项目代码,然后对源代码进行测试、编译,最终形成软件制品,如JAR包、WAR包等。
- 根据项目代码中的Dockerfile,开始构建Docker镜像,镜像中包含了软件的制品及运行所需的环境。
- 将构建好的Docker镜像推送到私有的镜像仓库Harbor中,进行统一的管理,方便后续下载使用。
- 根据项目代码中的YAML资源配置模板,通过脚本将其中的变量替换为本次构建实际的输入值,生成最终可以在Kubernetes集群中部署的YAML资源配置文件。
- 调用Kubernetes的API,执行部署。
- Kubernetes集群将依据YAML资源配置文件,从镜像仓库中拉取镜像,分配资源,并启动相关的容器和服务,开始对外提供服务。
2.4.2 CI/CD发布流水线流程及人员分工
使用Jenkins构建CI/CD发布流水线之后,工作流程实现了标准化,不仅减少了人工的工作量,而且降低了人工执行的故误操作率。同时原先大部分依靠人工来执行的工作都由流水线自动执行,因此人员的分工及工作内容可能也会与原先的不同,人员将更加专注于核心工作本身。
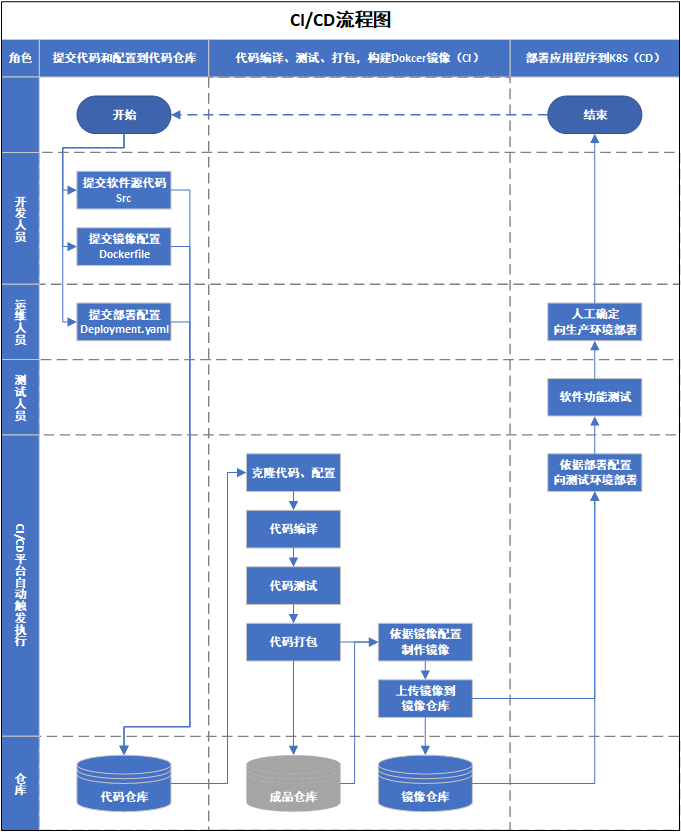
针对一个通用的软件项目来说,一般情况下涉及到的人员有开发人员、运维人员和测试人员。开发人员现在只需要提交自己的代码源码,以及将代码容器化Dockerfile(Dockerfile也可以由运维人员编写),而不用关心其他。运维人员则提交在Kubernetes中运行容器的配置文件。当所有的源代码和配置文件提交到代码仓库之后,Jenkins触发构建任务,进行自动的代码编译、代码测试、代码打包、制作镜像、上传镜像、部署到Kubernetes集群,当任务执行成功后,将得到一个部署好的、可用的应用系统。测试人员可以在系统中进行测试,以验证系统的功能。当测试通过之后,确认可以向生产环境部署,则可以人工确认,触发部署到生产环境的流水线,实现系统的上线。
因此,最终的人员分工及CI/CD发布的流程图如下图所示:
三、CI/CD发布流水线的实现
3.1 总览
本项目中,无论是前端的项目,还是后端的项目,二者的发布过程基本一致,都是开发、运维提交代码和配置之后,由Jenkins将代码编译并制作成容器镜像,最终再部署到Kubernetes集群中。因此实现时,在源代码的基础之上,需要加入以下三类文件:将源程序制作成镜像的配置文件(Dockerfile)、在Kubernetes集群中部署应用的配置文件(Template.yaml),以及定义CI/CD流水线的配置文件(Jenkinsfile)。
下面将介绍这三类文件的编写方式,并进行CI/CD流水线的发布和验证。
3.2 编写Dockerfile
项目代码分为两类,Vue.js和Java,二者的编译环境和步骤有区别,因此分开介绍。
3.2.1 前端Vue.js项目
Vue.js项目的编译和运行环境是nodejs,为了保证编译之后,在运行环境中拥有所有的依赖包,我们可以在构建镜像的过程中安装依赖包,再将项目代码打包到镜像中,形成最终的可以启动项目的镜像。
具体的制作镜像的Dockerfile文件内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 以node 8为基础镜像,alpine版本的镜像会小很多
FROM node:8-alpine
# 设定项目的主目录
WORKDIR /usr/src/app
# 复制项目代码到镜像中
COPY . .
# 安装项目依赖包,如果是生产系统,用如下的命令
# RUN npm install --only=production
RUN npm install -d --registry=https://registry.npm.taobao.org
# 暴露服务端口
EXPOSE 80
# 启动服务,根据package.json中的配置决定是 npm run xxx
CMD [ "npm", "run", "xxx" ]
3.2.2 后端Java项目
后端Java项目的编译环境是maven,编译之后将形成可以直接运行的jar包,运行环境是java,因此我们在maven环境中编译,然后将编译后的制品jar包打包到镜像中,形成最终可以穷项目的镜像。
具体的制作镜像的Dockerfile文件内容如下:
1
2
3
4
5
6
7
8
9
10
11
# 以java:8作为基础镜像,alpine版本的镜像会小很多
FROM java:8-jdk-alpine
# 将项目的制品jar包添加到镜像中的一个目录中,假设是 /project
ADD target/xxx.jar /project/xxx.jar
# 暴露服务端口
EXPOSE 8080
# 启动容器时执行的命令,运行test.jar
ENTRYPOINT ["java","-jar","/project/xxx.jar"]
3.3 编写YAML配置模板
由于前后端项目均为无状态应用,每个项目的功能模块都可以运行多个副本,对应同一个服务,达到负载均衡和高可用的目的。因此项目模块可以采用Kubernetes中的Deployment资源来运行,对应的服务采用Service资源运行,后端项目的服务端口不需要对集群外部开放,前端项目的服务可通过Ingress等方式对外暴露端口。
因此,最终的Template.yaml根据运行应用的不同,需要配置Deployment、Service、Ingress等资源。下面是前端项目的YAML配置模板,模板中可以配置变量,比如镜像的名称版本、服务的名称等,在实际部署时将会替换为实际的值。下例中,镜像的标签中设置了一个变量:TAG_ID。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: mall-web
labels:
app: mall-web
spec:
selector:
matchLabels:
app: mall-web
replicas: 2
template:
metadata:
labels:
app: mall-web
spec:
containers:
- name: mall
image: harbor.yuandingit.com/mall/mall-web:v1.0.TAG_ID
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: web
---
apiVersion: v1
kind: Service
metadata:
name: mall-web
spec:
selector:
app: mall-web
type: Cluster
ports:
- name: web
port: 80
targetPort: 80
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: mall-web
spec:
rules:
- host: mall.yuandingit.com
http:
paths:
- backend:
serviceName: mall-web
servicePort: 80
3.4 编写Jenkinsfile
Jenkinsfile中需要定义运行构建任务的agent,以及所需执行的步骤,下面是针对前端项目的Jenkinsfile文件的内容,其中的agent就是要执行构建任务的Jenkins-slave节点,stages是需要执行的构建步骤。文件中针对配置内容的说明,请参考:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
pipeline {
//声明执行构建任务的 agent,指明该agnet以POD的形式运行在名称为“k8s”的kubernetes集群中,agent的标签是“jenkins-salve-pod”
agent {
kubernetes {
cloud 'k8s'
label 'jenkins-slave-pod'
defaultContainer 'jnlp'
//agent pod的具体yaml配置,除了默认的jnlp容器之外,还定义了一个容器:docker。
//docker容器具备docker环境,可以挂在宿主机的docker.sock,形成docker in docker环境,可以构建和上传docker镜像。
yaml """
apiVersion: v1
kind: Pod
metadata:
labels:
app: jenkins-slave
spec:
securityContext:
runAsUser: 0
fsGroup: 0
hostAliases:
- ip: 192.168.51.203
hostnames:
- harbor.yuandingit.com
- rancher.yuandingit.com
containers:
- name: docker
image: harbor.yuandingit.com/cicd/docker:17.03.2-ce
imagePullPolicy: IfNotPresent
command: ["sleep","3600"]
volumeMounts:
- name: jenkinsdocker
mountPath: /var/run/docker.sock
volumes:
- name: jenkinsdocker
hostPath:
path: /var/run/docker.sock
type: Socket
serviceAccount: jenkins-admin
imagePullSecrets:
- name: harbor-yuandingit-com
"""
}
}
// 定义流水线具体执行的阶段(stage)和步骤(step),这里定义了四个阶段:“Clone Code”、“Replace Variable”,“Build Images”,“Deploy To K8s”。
// 每个阶段中定义了需要执行的步骤,每个步骤中定义了执行步骤的容器(container),以及具体执行的命令和内容。
stages {
stage('Clone Code') {
steps {
container('docker') {
git credentialsId: 'gitlab-zzl', url: 'http://gitlab.cicd/group-java/helloworld.git'
}
}
}
stage('Replace Variable') {
steps {
container('docker') {
sh 'sed -i s/"TAG_ID"/"${BUILD_ID}"/g Template.yaml'
}
}
}
stage('Build Images') {
steps {
container('docker') {
withDockerRegistry(credentialsId: 'harbor-admin', url: 'http://harbor.yuandingit.com') {
sh 'docker build -t harbor.yuandingit.com/mall/mall-web:v1.0.$TAG_ID .'
sh 'docker push harbor.yuandingit.com/mall/mall-web:v1.0.$TAG_ID'
}
}
}
}
stage('Deploy To K8s') {
steps {
container('docker') {
kubernetesDeploy configs: 'Template.yaml', kubeConfig: [path: ''], kubeconfigId: '51.200-kubeconfig', secretName: '', ssh: [sshCredentialsId: '*', sshServer: ''], textCredentials: [certificateAuthorityData: '', clientCertificateData: '', clientKeyData: '', serverUrl: 'https://']
}
}
}
}
}
3.5 配置CI/CD流水线任务
配置CI/CD流水线时,需要选择“流水线(Pipeline)”类型的任务,其中配置项目对应的代码仓库和使用的Jenkinsfile即可,具体配置方法如下:
-
新建任务
新建一个任务(Job),类型选择“流水线(Pipeline)”。 -
配置任务触发器
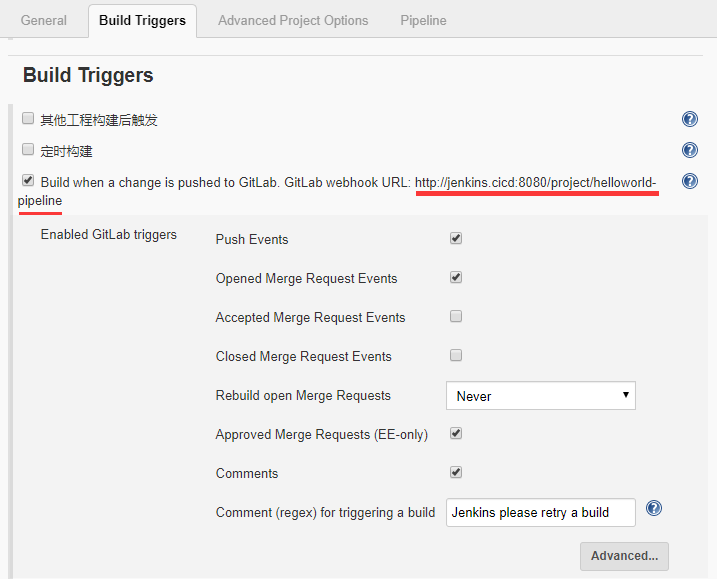
在“Build Triggers”中配置触发该构建任务的条件,可以配置为定时构建(轮询SCM也是定时构建),或者配置为自动触发构建。配置为Gitlab自动触发构建时,需要安装gitlab webhook插件,并需要将此处的 URL 配置到gitlab项目中的webhook中(gitlab中设置的路径为 进入项目→“设置”→“集成”,然后填写url,添加webhook,测试成功返回HTTP200即可)。
-
配置流水线
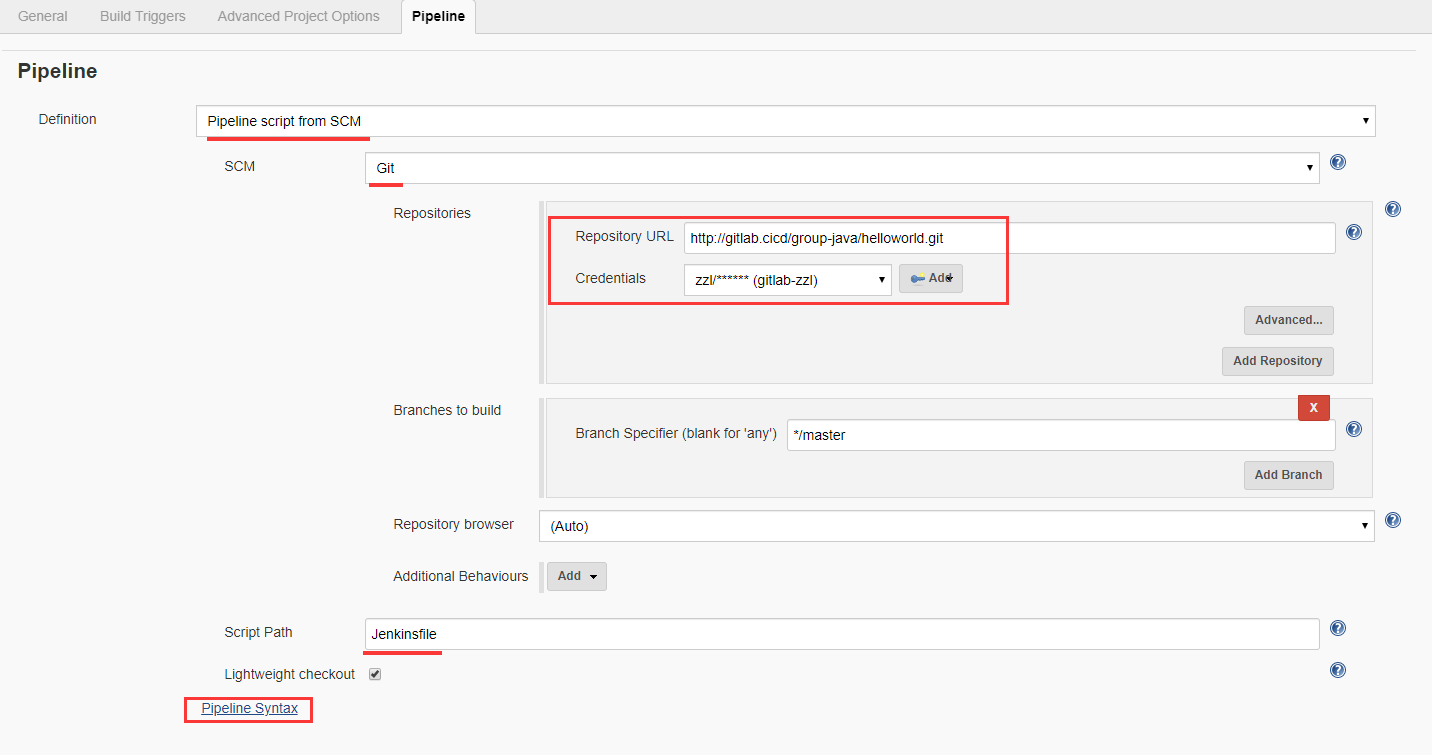
在“Pipeline”中配置本任务的流水线,因为流水线的配置文件Jenkinsfile文件是放在代码仓库中的,因此这里需要配置代码仓库的地址,并选择相应的Jenkinsfile配置文件。
下面是各个配置项的选择和填写方法:
Definition:定义,确定本次任务的流水线配置文件的方式,一种是“Pipeline Script”,即在这里直接填写Jenkinsfile的内容;一种是“Pipeline Script from SCM”,即表明Jenkinsfile是来自于代码仓库的。因为我们的Jenkinsfile是放在代码仓库中管理的,所以选择“Pipeline Script from SCM”。
SCM:源代码管理,表明代码仓库的类型,比如Git、SVN等等。
Repository URL:代码仓库地址,填写源代码的代码仓库地址,注意:执行构建任务的Jenkins-slave节点必须能够访问并从该地址下载代码。
Credentials:访问代码仓库的凭据,即登录代码仓库的用户名和密码。
Branch to Build:Git代码仓库的分支,即构建时拉取代码的分支,默认是“Master”。
Script Path:流水线脚本的路径,即Jenkinsfile的路径,该路径是相对于源代码的根目录的,假设配置文件名称为Jenkinsfile,且在源代码的最顶层,那么此处可以直接填写Jenkinsfile即可。
3.6 方案验证
在方案验证环节,需要验证的主要内容有:代码提交后是否触发Jenkins中的构建任务?构建任务执行的过程和结果是否正常?镜像仓库中是否有指定版本的镜像上传?Kubernets集群中的应用是否进行了升级?
-
Jenkins任务触发的验证
Jenkins中任务的触发方式有多种,比如定时轮询和代码仓库自动触发。使用代码仓库自动触发构建时,当代码仓库有代码PUSH上来时,在Jenkins中可以看到对应的任务会自动启动,且任务的上有类似“Started by GitLab push by xxx”的标识,说明该任务是由Gitlab的Push动作触发的。 -
监控Jenkins任务的执行过程
在Jenkins中,进入对应的任务,可以看到相关的构建历史,选择正在运行的构建,进入“控制台输出(Console Output)”,可以查看构建任务的执行日志。如果使用blueocean版本的Jenkins,可以进入blueocean中查看日志。在日志中将会看到所有的执行日志,包括agent的创建日志、每个步骤的执行日志、Docker镜像的构建过程日志、Kubernetes部署资源的日志、以及错误日志。
在构建任务执行时,可以到Kubernetes集群中,可以看到启动的Jenkins-slave POD,里面包含定义好的容器,实际的构建任务在这些容器中运行。
通常情况下,构建任务在执行的过程中,如果前面的步骤出现错误,任务将会自动跳过后续的步骤并结束。 -
确认镜像构建及上传到镜像仓库
当任务中的镜像构建步骤执行成功后,在Harbor镜像仓库中可以看到对应版本的镜像。 -
观察应用的升级过程
构建任务的最后一步通常是将应用部署到Kubernetes集群中,当任务执行成功后,在Kubernetes集群中可以看到对应的应用根据设置的升级策略在执行滚动升级,比如先停止旧的POD,再启动新的POD,新的POD使用的是新的镜像,应用正常启动后,就可以访问到新版本的应用。
四、总结
我们通过一系列的文章,从业务的微服务化拆分、构建容器云管理平台、构建CI/CD发布流水线宪哥方面介绍了传统业务的容器化改造方案。其中构建容器云管理平台、搭建私有镜像仓库、搭建私有代码仓库、部署CI/CD持续集成交付工具集均属于基础平台的构建。在此基础之上通过配置对应的CI/CD发布流水线实现了从代码提交、编译,到容器镜像的构建,再到部署到容器云管理平台,实现了业务容器化改造和部署的过程,最终达到一键式部署、一次构建打包、一次配置发布的目标,这部分属于DevOps体系的构建。
业务容器化改造时,需要围绕开发、测试和运维三个角色,构建更利于组织内部协调工作的DevOps文化,不断完善和提高企业的标准化流程,从管理层面解决容器化之后管理混乱和发布上线困难的问题。
业务容器化改造实践的系列文章暂时告一段落,希望这一系列的文章对大家进行业务容器化改造时能有一定的启发和帮助,也欢迎各位读者留言讨论,共同进步。